Что такое peer to peer. Рассмотрим некоторые алгоритмы поиска в пиринговых сетях, ограничившись основными методами поиска по ключевым словам
Дмитрий ЛАНДЭ
К
ак
это часто бывает, все начиналось с попытки обойти Закон. У
некоторых людей появилось желание обмениваться через Интернет
представленными в электронной форме и защищенными авторскими
правами произведениями.
Логика таких действий вполне понятна. Допустим, Айван купил
в магазине книгу. Авторские права не нарушены. Айван прочитал
книгу и дал ее почитать Питеру. Питер книгу не покупал, автору не
досталась его часть авторского вознаграждения. Питер прочитал
книгу, воспринял информацию. Нарушил ли он Закон? Пожалуй, нет.
Питер передал книгу Стивену, который, в свою очередь, передал
другую, легально купленную книгу, Айвану. Три товарища, как
говорят полицейские - три фигуранта, однако нарушений вроде бы
нет.
Допустим, друзей не три, а тридцать. Нарушен ли Закон?
Каждый автор недополучает двадцать девять вознаграждений.
Формируется некая сетевая структура, где каждый связан с каждым,
без выделенного центра. В технике такие сети назы-ваются
децентрализованными, в отличие от централизованных. Аналог
централизованной сети - публичная библиотека. Айван, Питер и
Стивен пошли в публичную библиотеку и прочитали выбранные книги,
восприняли информацию. Нарушает ли библиотека авторское право?
Вопрос не риторический, а очень даже актуальный, широко
обсуждаемый общественностью. Что бы ни говорил Закон, какие бы
поправки не вносились, история человеческой цивилизации говорит о
том, что библиотеки - это благо.
А теперь допустим, что собрались не три и не тридцать, а
три миллиона друзей и обмениваются книгами. Где грань, скольким
друзьям можно ими обмениваться законно, а скольким нельзя? И
почему только книгами, как-никак XXI век на дворе... Книги
переводятся в электронный вид (и этот процесс, по-видимому,
необратим), появляются аудиокниги, фильмы в современных компактных
форматах, мультимедийные энциклопедии, да и прочие программы,
включая дистрибутивы операционных систем.
Во многих странах сегодня пришли к заключению - публичные
централизованные электронные библиотеки (читайте: «серверы»)
произведений, защищенных авторским правом, - вне Закона. Сервер
имеет владельца, его можно легко выявить, а сервер закрыть.
Многие помнят историю сетевой службы Napster, глобальной
файловой биржи конца двадцатого века. В июне 2000 года было
вынесено судебное постановление о ее закрытии, к этому времени
Napster пользовались 40 млн. пользователей. Служба Napster была
централизованной - она требовала наличия центрального сервера,
который обеспечивал функционирование всей системы в целом. При
этом революционность системы как раз и заключалась в элементах
децентрализации, ее пользователи могли общаться друг с другом
напрямую, предоставляя для скачивания свои файлы.
Для обхода Закона, учитывая грустную историю службы
Napster, стали разрабатывать файлообменные сети с высокой степенью
децентрализации. Конечно, за такую возможность пришлось платить
функциональностью.
Именно о таких системах будет идти речь ниже, однако не
столько о тех аспектах, которые до сих пор представляются
нелегальными, а о возможностях, которые оказались вполне законными
и широко востребованными. Наряду с некоторыми недостатками
децентрализованного подхода к организации информационных сетей
обнаружились такие преимущества, которые обусловили их широкое
применение в обороне, государственном управлении, науке и бизнесе.
Итак, речь пойдет о децентрализованных или пиринговых сетях
(от англ. peer-to-peer, P2P - один на один) - компьютерных сетях,
основанных на равноправии участников. В таких сетях отсутствуют
выделенные серверы, а каждый узел (peer) является как клиентом,
так и сервером. На практике пиринговые сети состоят из узлов,
каждый из которых взаимодействует лишь с некоторым подмножеством
других узлов (из-за ограниченности ресурсов). В отличие от
архитектуры «клиент–сервер» такая организация позволяет сохранять
работоспособность сети при любом количестве и любом сочетании
доступных узлов.
Сегодня пиринговые сети настолько развились, что WWW уже не
является самой крупной информационной сетью по ресурсам и
порождаемому интернет-трафику. Известно, что трафик, объем
информационных ресурсов (в байтах), количество узлов пиринговых
сетей, если их рассматривать в совокупности, ничем не уступают
сети WWW. Более того, трафик пиринговых сетей составляет 70% всего
интернет-трафика (рис. 1)! При этом можно отметить два очень
важных аспекта: во-первых, о пиринговых сетях очень мало пишут в
научной литературе, а во-вторых, проблемы поиска и уязвимости
пиринговых сетей, как крупнейшего «белого пятна» современных
коммуникаций, пока остаются открытыми.
«Клиент-сервер» и P2P
Централизованная архитектура «клиент-сервер» подразумевает,
что сеть зависит от центральных узлов (серверов), обеспечивающих
подключенные к сети терминалы (т.е. клиентов) необходимыми
сервисами. В этой архитектуре ключевая роль отводится серверам,
которые определяют сеть независимо от наличия клиентов. Очевидно,
что рост количества клиентов сети типа «клиент–сервер» приводит к
росту нагрузок на серверную часть. Таким образом, на определенном
уровне развития сети она может оказаться перегруженной.
Архитектура P2P, как и «клиент– сервер», также является
распределенной. Отличительная черта P2P заключается в том, что это
децентрализованная архитектура, где не существует понятий «клиент»
и «сервер». Каждый объект в сети (равноправный узел) имеет
одинаковый статус, который позволяет выполнять как функции клиента,
так и сервера. Несмотря на то, что все узлы имеют одинаковый
статус, реальные возможности их могут существенно различаться.
Достаточно часто пиринговые сети дополняются выделенными серверами,
несущими организационные функции, например авторизацию.
Децентрализованная пиринговая сеть, в отличие от
централизованной, становится более производительной при увеличении
количества узлов, подключенных к ней. Действительно, каждый узел
добавляет в сеть P2P свои ресурсы (дисковое пространство и
вычислительные возможности), в результате суммарные ресурсы сети
увеличиваются.
Области применения
Существует несколько областей применения пиринговых сетей,
объясняющих их растущую популярность. Назовем некоторые из них.
Обмен файлами. P2P выступают альтернативой FTP-архивам, которые утрачивают перспективу ввиду значительных информационных перегрузок.
Распределенные вычисления. Например, такой P2P-проект, как SETI@HOME (распределенный поиск внеземных цивилизаций) продемонстрировал огромный вычислительный потенциал для распараллеливаемых задач. В настоящий момент в нем принимают участие свыше трех миллионов пользователей на бесплатной основе.
Обмен сообщениями. Как известно, ICQ – это P2P-проект.
Интернет-телефония.
Групповая работа. Сегодня реализованы такие сети групповой работы, как Groove Network (защищенное пространство для коммуникаций) и OpenCola (поиск информации и обмен ссылками).
Существует много областей, где успешно применяется
P2P-технология, например, параллельное программирование,
кэширование данных, резервное копирование данных.
Общеизвестно,
что система доменных имен (DNS) в сети Интернет также фактически
является сетью обмена данными, построенной по принципу Р2Р.
Самой
популярной службой интернет-телефонии является Skype (www.skype.com),
созданная в 2003 году шведом Никласом Зеннстромом и датчанином
Янусом Фриисом, авторами известной пиринговой сети KaZaA.
Построенная в архитектуре P2P служба Skype сегодня охватывает
свыше 10 млн. пользователей. В настоящее время Skype принадлежит
интернет-аукциону eBay, который приобрел ее за 2,5 млрд. долларов.
Рис. 1. Распределение трафика Интернет по протоколам (а) и между P2P-сетями (б) (данные по Германии, 2007 г.)
Реализацией технологии Р2Р является также популярная в настоящее время система распределенных вычислений GRID. Еще одним примером распределенных вычислений может служить проект distributed.net, участники которого занимаются легальным взломом криптографических шифров, чтобы проверить их надежность.
Стандартизация в области P2P
P2P - это не только сети, но
еще и сетевой протокол, обеспечивающий возможность создания и
функционирования сети равноправных узлов, их взаимодействия.
Множество узлов, объединенных в единую систему и взаимодействующих
в соответствии с протоколом P2P, образуют пиринговую сеть. Для
реализации протокола P2P используются клиентские программы,
обеспечивающие функциональность как отдельных узлов, так и всей пиринговой сети.
P2P относятся к прикладному
уровню сетевых протоколов и являются наложенной сетью,
использующей существующие транспортные протоколы стека TCP/IP -
TCP или UDP. Протоколу P2P посвящено несколько основополагающих
документов сети Интернет - RFC (в частности, последний датируется
2008 годом - RFC 5128 State of Peer-to-Peer (P2P) Communication
across Network Address Translators).
В настоящее время при
реализации пиринговых сетей используются самые различные
методологии и подходы. В частности, компания Microsoft разработала
протоколы для P2P-сетей Scribe и Pastry. Поддержка протокола PNRP
(Peer Name Resolution Protocol), также относящегося к
P2P-системам, была включена в состав Windows Vista.
Одну из удачных попыток
стандартизации протоколов P2P предприняла компания Sun
Microsystems в рамках проекта JXTA. Этот проект реализуется с
целью унифицированного создания P2P-сетей для различных платформ.
Цель проекта JXTA - разработка типовых инфраструктурных решений и
способов их использования при создании P2P-приложений для работы в
неоднородных средах.
В рамках проекта JXTA
определено шесть протоколов, на основе которых могут создаваться
прикладные системы:
Peer Discovery Protocol (PDP). Узлы используют этот протокол для поиска всех открытых JXTA-ресурсов. Низкоуровневый протокол PDP обеспечивает базовые механизмы поиска. Прикладные системы могут включать собственные высокоуровневые механизмы поиска, которые реализованы поверх PDP.
Peer Resolver Protocol (PRP). Этот протокол стандартизирует формат запросов на доступ к ресурсам и сервисам. При реализации этого протокола с узла может быть послан запрос и получен на него ответ.
Peer Information Protocol (PIP). PIP используется для определения состояния узла в сети JXTA. Узел, получающий PIP-сообщение, может в полной или сокращенной форме переслать ответ о своем состоянии либо проигнорировать это сообщение.
Peer Membership Protocol (PMP). Узлы используют этот протокол для подключения и выхода из группы.
Pipe Binding Protocol (PBP). В JXTA узел получает доступ к сервису через канал (pipe). С помощью PBP узел может создать новый канал для доступа к сервису или работать через уже существующий.
Endpoint Routing Protocol (ERP). Используя этот протокол, узел может пересылать запросы к маршрутизаторам других узлов для определения маршрутов при отправке сообщений.
Алгоритмы поиска в пиринговых сетях
Поскольку
сегодня в перенасыщенном информацией мире задача полноты поиска
отводится на второй план, то главная задача поиска в пиринговых
сетях сводится к быстрому и эффективному нахождению наиболее
релевантных откликов назапрос, передаваемый от узла всей сети. В
частности, актуальна задача - уменьшение сетевого трафика,
порождаемого запросом (например, пересылки запроса по
многочисленным узлам), и в то же время получение наилучших
характеристик выдаваемых документов, т.е. наиболее качественного
результата.
Следует отметить,
что, в отличие от централизованных систем, организация
эффективного поиска в пиринговых сетях - открытая
исследовательская проблема.
В большинстве
пиринговых сетей, ориентированных на обмен файлами, используется
два вида сущностей, которым приписываются соответствующие
идентификаторы (ID): узлы (peer) и ресурсы, характеризующиеся
ключами (key), т.е. сеть может быть представлена двумерной
матрицей размерности MN, где M - количество узлов, N - количество
ресурсов. В данном случае задача поиска сводится к нахождению ID
узла, на котором хранится ключ ресурса. На рис. 2.
представлен процесс поиска ресурса с ключом 14, запускаемый с узла
ID0.
В данном случае с
узла ID0 запускается поиск ресурса с ключом 14. Запрос проходит
определенный маршрут и достигает узла, на котором находится ключ
14. Далее узел ID14 пересылает на ID0 адреса всех узлов,
обладающих ресурсом, соответствующим ключу 14.

Рис. 2. Модель поиска ресурса по ключу
Рассмотрим некоторые алгоритмы поиска в пиринговых сетях, ограничившись основными методами поиска по ключевым словам.
Метод широкого первичного поиска
Рис. 3. Некоторые модели поиска в пиринговых сетях
Метод широкого первичного поиска (Breadth First
Search, BFS) широко используется в реальных файлообменных сетях
P2P, таких как, например, Gnutella. Метод BFS (рис. 3a
) в
сети P2P размерности N реализуется следующим образом. Узел q
генерирует запрос, который адресуется ко всем соседям (ближайшим,
по некоторым критериям, узлам). Когда узел p получает запрос,
выполняется поиск в ее ло-кальном индексе. Если некоторый узел r
принимает запрос (Query) и отрабатыват его, то он генерирует
сообщение QueryHit, чтобы возвратить результат. Сообщение QueryHit
включает информацию о релевантных документах, которая доставляется
по сети запрашивающему узлу.
Когда узел q получает QueryHits от более чем
одного узла, он может загрузить файл с наиболее доступного
ресурса. Сообщения QueryHit возвращаются тем же путем, что и
первичный запрос.
В BFS каждый запрос вызывает чрезмерную
нагрузку сети, так как он передается по всем связям (в том числе и
узлам с высоким временем ожидания). Поэтому узел с низкой
пропускной способностью может стать узким местом. Однако есть
метод, позволяющий избежать перегрузки всей сети сообщениями. Он
заключается в приписывании каждому запросу параметра времени жизни
(time-to-level, TTL). Параметр TTL определяет максимальное число
переходов, по которому можно пересылать запрос.
При типичном поиске начальное значение для TTL
составляет обычно 5–7, которое уменьшается каждый раз, когда
запрос пересылается на очередной узел. Когда TTL становится равным
0, сообщение больше не передается. BFS гарантирует высокий уровень
качества совпадений за счет большого числа сообщений.
Метод случайного широкого первичного поиска
Метод случайного широкого первичного поиска (Random Breadth First Search, RBFS) был предложен как улучшение «наивного» подхода BFS. В методе RBFS (рис. 3b ) узел q пересылает поисковое предписание только части узлов сети, выбранных в случайном порядке. Какая именно часть узлов - это параметр метода RBFS. Преимущество RBFS заключается в том, что не требуется глобальной информации о состоянии контента сети; узел может получать локальные решения так быстро, как это потребуется. С другой стороны, этот метод вероятностный. Поэто-му некоторые большие сегменты сети могут оказаться недостижимыми (unreachable).
Интеллектуальный поисковый механизм
Интеллектуальный поисковый механизм (Intelligent
Search Mecha-nism, ISM) - новый метод поиска в сетях P2P (рис.
3c
). С его помощью достигается улучшение скорости и
эффективности поиска информации за счет минимизации затрат на
связи, то есть на число сообщений, передающихся между узлами, и
минимизации количества узлов, которые опрашиваются для каждого
поискового запроса. Чтобы достичь этого, для каждого запроса
выбираются лишь те узлы, которые наиболее соответствуют данному
запросу.
Механизм интеллектуального поиска состоит из
двух компонентов:
Профайла, который узел q строит для каждого
из соседних узлов. Профайл содержит последние ответы каждого узла.
Механизма ранжирования профайлов узлов (ранга
релевантности). Ранг релевантности используется, чтобы выбрать
соседей, которые будут давать наиболее релевантные документы на
запрос.
Механизм профайлов служит для того, чтобы
сохранять последние запросы, а также количественные характеристике
результатов поиска. При реализации модели ISM используется единый
стек запросов, в котором сохраняется по T запросов для q соседних
узлов. Как только стек заполняется, узел прибегает к правилу
замены «последнего наименее используемого» для сохранения
последних запросов.
Метод ISM эффективно работает в сетях, где узлы
содержат некоторые специализированные сведения. В частности,
исследование сети Gnutella показывает, что качество поиска очень
зависит от «окружения» узла, c которого поступает запрос. Еще одна
проблема в методе ISM состоит в том, что поисковые сообщения могут
зацикливаться, не в состоянии достичь некоторых частей сети. Чтобы
разрешить эту проблему, обычно выбирается небольшое случайное
подмножество узлов, которое добавляется к набору релевантных узлов
для каждого запроса. В результате механизм ISM стал охватывать
большую часть сети.
Метод «большинства результатов по прошлой эвристике»
В методе «большинства результатов по прошлой
эвристике» (>RES) каждый узел пересылает запрос подмножеству своих
узлов, образованному на основании некоторой обобщенной статистики
(рис. 3d
).
Запрос в методе >RES является
удовлетворительным, если выдается Z или больше результатов (Z -
некоторая постоянная). В методе >RES узел q пересылает запросы к k
узлам, выдавшим наибольшие результаты для последних m запросов. В
экспериментах k изменялось от 1 до 10, и таким путем метод >RES
варьировался от BFS до подхода глубинного первичного поиска (Depth-first-search).
Метод >RES подобен методу ISM, который
рассматривался ранее, но использует более простую информацию об
узлах. Его главный недостаток по сравнению с ISM - отсутствие
анализа параметров узлов, содержание которых связано с запросом.
Поэтому метод >RES характеризуется скорее как количественный, а не
качественный подход. Из опыта известно, что >RES хорош тем, что он
маршрутизирует запросы в большие сегменты сети (которые, возможно,
также содержат более релевантные ответы). Он также захватывает
соседей, которые менее перегружены, начиная с тех, которые обычно
возвращают больше результатов.
Метод случайных блужданий
Ключевая идея метода случайных блужданий (Random
Walkers algorithm, RWA) заключается в том, что каждый узел
случайным образом пересылает сообщение с запросом, именуемое
«посылкой», одному из своих соседних узлов. Чтобы сократить время,
необходимое для получения результатов, идея одной «посылки»
расширена до «k посылок», где k - число независимых посылок,
последовательно запущеных от исходного узла.
Ожидается, что «k посылок» после T шагов
достигнет тех же результатов, что и одна посылка за kT шагов. Этот
алгоритм напоминает метод RBFS, но в RBFS предполагается
экспоненциальное увеличение пересылаемых сообщений, а в методе
случайных блужданий - линейное. Оба метода - и RBFS, и RWA - не
используют никаких явных правил, чтобы адресовать поисковый запрос
к наиболее релевантному содержанию.
Еще одной методикой, подобной RWA, является
адаптивный вероятностный поиск (Adaptive Probabilistic Search, APS).
В APS каждый узел развертывает локальный индекс, содержащий
значения условных вероятностей для каждого соседа, который может
быть выбран для следующего перехода для будущего запроса. Главное
отличие от RWA в данном случае - это то, что в APS узел использует
обратную связь от преды-дущих поисков вместо полностью случайных
переходов.
Примеры файлообменных пиринговых сетей
Отдельного рассмотрения заслуживают
файлообменные P2P-сети, которые охватывают в настоящее время свыше
150 млн. узлов. Рассмотрим наиболее популярные в настоящее время
пиринговые сети, такие как Bittorrent, Gnutella2 и eDonkey2000.
![]()
Сеть BitTorrent
(битовый поток) была
создана в 2001 году. В соответствии с протоколом BitTorrent файлы
передаются не целиком, а частями, причем каждый клиент, закачивая
эти части, в это же время отдает их другим клиентам, что снижает
нагрузку и зависимость от каждого клиента-источника и обеспечивает
избыточность данных. С целью инициализации узла в сети Bittorrent
(www.bittorrent.com) клиентская программа обращается к выделенному
серверу (tracker), предоставляющему информацию о файлах, доступных
для копирования, а также статистическую и маршрутную информацию об
узлах сети. Сервер и после инициализации «помогает» узлам
взаимодействовать друг с другом, хотя последние версии клиентских
программ требуют наличия сервера только на стадии инициализации,
приближаясь к идеалу концепции peer-to-peer.
Если узел «хочет» опубликовать файл, то
программа разделяет этот файл на части и создает файл метаданных (torrent
file) с информацией о частях файла, их местонахождении и узле,
который будет поддерживать распространение этого файла.
Существует множество совместимых
программ-клиентов, написанных для различных компьютерных платформ.
Наиболее распространенные клиентские программы - Azureus,
BitTorrent_client, μTorrent, BitSpirit, BitComet, BitTornado,
MLDonkey.
![]()
В 2000 году была создана одна из первых
пиринговых сетей Gnutella
(www.gnutella.com), алгоритм
которой в настоящее время усовершенствован. Сегодня популярность
завоевала более поздняя ветвь этой сети - Gnutella2
(www.gnutella2.com), созданная три года спустя, в 2003-м, которая
реализует открытый файлообменный P2P-протокол, используемый
программой Shareaza.
В соответствии с протоколом Gnutella2 некоторые
узлы становятся концентраторами, остальные же являются обычными
узлами (leaves). Каждый обычный узел имеет соединение с
одним-двумя концентраторами. Gnutella2 реализует информационный
поиск с помощью метода блужданий. В соответствии с этим протоколом
у концентратора есть связь с сотнями узлов и десятки соединений с
другими концентраторами. Каждый узел пересылает концентратору
список идентификаторов ключевых слов, по которым могут быть
найдены публикуемые ресурсы. Для улучшения качества поиска
используются также метаданные файлов - информация о содержании,
рейтинги. Допускается возможность «размножения» информации о файле
в сети без копирования самого файла.
Для передаваемых пакетов в сети разработан
собственный формат, реализующий возможность наращивания
функциональности сети путем добавления дополнительной служебной
информации. Запросы и списки ID ключевых слов в Gnutella2
пересылаются на концентраторы по UDP.
Наиболее распространенные программы для
Gnutella2 - это Shareaza, Kiwi, Alpha, Morpheus, Gnucleus, Adagio
Pocket G2, FileScope, iMesh, MLDonkey.
![]()
Сеть EDonkey2000
была создана также в
2000 году. Информация о наличии файлов в ней публикуется клиентом
на многочисленных серверах в виде ed2k-ссылок, использующих
уникальный ID ресурса. Поиск узлов и информации в EDonkey2000
обеспечивают выделенные серверы. В настоящее время в сети
существует около 200 серверов и порядка миллиарда файлов. Число
пользователей EDonkey2000 составляет 10 млн. человек.
При работе каждый клиент EDon-key2000 связан с
одним из серверов. Клиент сообщает серверу, какие файлы он
предоставляет в общий доступ. Каждый сервер поддерживает список
всех общих файлов клиентов, подключенных к нему. Когда клиент
что-то ищет, он посылает поисковый запрос своему основному
серверу. В ответ сервер проверяет все файлы, которые ему известны,
и возвращает клиенту список файлов, удовлетворяющих его запросу.
Возможен поиск по нескольким серверам сразу. Такие запросы и их
результаты передаются через протокол UDP, чтобы уменьшить загрузку
канала и количество подключений к серверам. Эта функция особенно
полезна, если поиск на сервере, к которому клиент подключен в
настоящее время, дает низкий результат.
Когда клиент сети EDonkey2000 копирует желаемый
ресурс, он делает это одновременно из нескольких источников с
помощью протокола MFTP (Multisource File Transfer Protocol).
С 2004 года в состав сети EDonkey2000
интегрирована сеть Overnet
(www.overnet.com) - полностью
децентрализованная система, позволяющая осуществлять
взаимодействие между узлами без «привязки» к серверам, для чего
используется DHT-протокол Kademlia.Такая интеграция разных сетей и
дополнительная верификация способствовали большему развитию сети
EDonkey2000.
Самой популярной для сети EDon-key2000
клиентской программой с закрытым кодом является программа eDonkey,
однако существует и клиент с открытым программным кодом - eMule,
который, помимо сети EDon-key2000, может задействовать еще одну
сеть P2P - Kad Network.
Уязвимости пиринговых сетей
Следует признать, что помимо названных выше
преимуществ пиринговых сетей им присущ также ряд недостатков.
Первая группа недостатков связана со сложностью
управления такими сетями, по сравнению с клиент-серверными
системами, если их использовать в автоматизированных системах
управления. В случае применения сети типа P2P приходится
направлять значительные усилия на поддержку стабильного уровня ее
производительности, резервное копирование данных, антивирусную
защиту, защиту от информационного шума и других злонамеренных
действий пользователей.
Следует отметить, что пиринговые сети время от
времени подвергаются вирусным атакам, начало которым в 2002 году
положил сетевой червь Worm.Kazaa.Benjamin, распространяющийся по
пиринговой сети KaZaA.
Еще одна проблема P2P-сетей связана с качестом
и достоверностью предоставляемого контента. Серьезной проблемой
является фальсификация файлов и распространение
фальшивых ресурсов.
Кроме того, защита распределенной сети от
хакерских атак, вирусов и троянских коней является очень сложной
задачей. Зачастую информация с данными об участниках P2P-сетей
хранится в открытом виде, доступном для перехвата. Серьезной
проблемой также является возможность фальсификации ID узлов.
Автор рассмотрел модель гибридной пиринговой
сети с выделенными узлами (рис. 4
), связывающими отдельные
узлы и обеспечивающими ведение поисковых каталогов.

Рис. 4. Гибридная пиринговая сеть с выделенными серверами
В модели предполагалось, что существует N
узлов, каждый из которых логически связан в среднем с n (n << N)
количеством узлов. Для обеспечения поиска существует M поисковых
узлов, каждый из которых, в свою очередь, соединен с некоторым
количеством узлов; этим узлам он доступен как поисковый каталог.
Объемы каталогов распределены в соответствии с экспоненциальным
законом, т.е. i-й поисковый каталог соединен с k exp{ai} узлами,
где k и a - некоторые константы. Такая закономерность
распределения поисковых узлов, действительно, часто наблюдается на
практике.
Задача анализа уязвимости заключалась в том,
каким образом нарушится информационная связность пиринговой сети
при выводе из строя некоторого количества ведущих поисковых
каталогов.
Полученные расчеты подтвердили высокую
информационную устойчивость пиринговой сети, построенной в
соответствии с данными критериями, к удалению случайных поисковых
узлов. Вместе с тем, очень высока зависимость от удаления
наибольших узлов, что приводит к экспоненциальному снижению таких
показателей, как минимальная длина пути между узлами и коэффициент
кластерности.
Заключение
По сравнению с клиент-серверной архитектурой
P2P обладает такими преимуществами, как самоорганизованность,
отказоустойчивость к потере связи с узлами сети (высокая
живучесть), возможность разделения ресурсов без привязки к
конкретным адресам, увеличение скорости копирования информации за
счет использования сразу нескольких источников, широкая полоса
пропускания, гибкая балансировка нагрузки.
Благодаря таким характеристикам, как
живучесть, отказоустойчивость, способность к саморазвитию, пиринговые сети
находят все большее применение в системах управления предприятиями
и организациями (например, Р2Р-технология сегодня применяется в
Государственном департаменте США).
Существует много областей, где P2P-технология
успешно работает, например, параллельное программирование,
кэширование данных, резервное копирование данных.
Отдельно следует отметить недостатки, присущие
файлообменным сетям общего доступа. Самая большая проблема -
легитимность контента, передаваемого в таких P2P-сетях.
Неудовлетворительное решение этой проблемы привело уже к
скандальному закрытию многих подобных сетей. Следует заметить,
что, несмотря на многочисленные иски, направленные против
пиринговых сетей, в апреле этого года Европейский парламент
отказался «криминализировать» P2P.
Есть и другие проблемы, имеющие социальную
природу. Так, в системе Gnutella, например, 70% пользователей не
добавляют вообще никаких файлов в сеть. Более половины ресурсов с
этой сети предоставляется одним процентом пользователей, т.е. сеть
эволюционирует в направлении клиент-серверной архитектуры.
Дмитрий ЛАНДЭ
, СиБ
д.т.н., зам. директора ИЦ ElVisti
Бесплатный P2P-клиент с открытым кодом, для работы с сетью Direct Connect. Позволяет свободно скачивать файлы, расшаренные другими пользователями этой сети.
О пиринговых сетях (p2p)
Сеть Direct Connect по своей структуре чем-то напоминает тот же BitTorrent .
Хаб Хаб (англ. hub, ступица колеса, центр) - узел сети.Трекер - сервер сети BitTorrent, координирующий её клиентов.
Здесь тоже нет централизованной системы поиска, а для того, чтоб найти какой-либо файл, нужно посетить один из специальных серверов – хабов (аналогично трекерам на BitTorrent).
Соединившись с хабом, Вы получите список пользователей, подключенных к нему. Однако соединение может не произойти, если Вы не расшарили (не выложили для скачивания) нужного объема информации. Обычно от 2 до 10 Гб.
Если соединение все же произошло, то Вы имеете возможность либо ввести на поиск имя интересующего Вас файла, либо вести поиск вручную, заходя к каждому пользователю.
Принцип работы сети должен быть в общих чертах понятен. Теперь приступим к рассмотрению самого клиента для Direct Connection.
Установка StrongDC++
Скачав архив с программой, запускаем исполняемый файл и программа установится в папку «Program files» на вашем компьютере.
Если в конце установки Вы не убрали соответствующую галочку, то программа автоматически запустится.
Данная версия уже на русском языке, но если Вы скачали английскую версию, то русифицировать программу можно с помощью соответствующего файла с расширением xml , лежащего в нашем архиве с программой.
Когда русификатор скачан, его нужно установить. Для этого выбираем в меню настроек программы пункт «Appearance» и в поле Language file нажмем кнопку «Browse», чтобы выбрать местоположение файла sDC+++russian.xml (название файла русификатора).
После проведения всех манипуляций перезапустите программу и получите полнофункциональную русскую версию!
Настройка StrongDC++
Теперь настроим уже русскую версию Strong DC ++.

В меню «Общие» следует указать свой ник, E-mail, а также скорость отдачи файлов. Поле «Описание» можно оставить пустым (это типа Ваш комментарий).
IP-адрес - цифровой адрес компьютера в сети, например: 192.0.3.244.В «Настройках соединения» можно указать свой IP-адрес и некоторые другие данные. Особое внимание следует обратить на «Настройки входящих соединений».
Лучше использовать пассивное соединение через файервол (в противном случае файлы других пользователей у Вас не будут отображаться).
Прокси-сервер - промежуточный сервер.Трафик исходящих соединений можно перенаправить на прокси сервер, а можно оставить напрямую (скорость будет выше).
Затем выберем пункт «Скачка» и настроим папки для скачки по умолчанию и для хранения временных файлов.
А теперь – самое главное!!! Надо расшарить свои файлы. Для этого заходим в меню «Мои файлы (шара)» и в открывшемся справа окошке выбираем те файлы и папки, к которым Вы хотите открыть доступ.

После того, как Вы выберите какой-либо файл, у Вас отобразится следующее окно прогресса.

Начало работы с StrongDC++
По истечению хеширования файлов, можно уже приступать к непосредственной работе с программой. Нажмите кнопку «OK» внизу и перед Вами появится главное окно программы.
Для того чтобы начать поиск нужных файлов, первым делом придётся подключиться к одному из многочисленных хабов.
Для этого следует нажать кнопку «Инет хабы» на панели инструментов, а далее выбрать один из списков инет хаб-листов и нажать кнопку «Обновить».

Если Вы знаете имя нужного Вам хаба или конкретного юзера, то проще производить поиск, используя фильтр.
Когда нужный хаб найден, можно переходить к нему, дважды кликнув левой кнопкой мыши по названию. Если объем расшаренных Вами данных соответствует требованиям хаба, то Вы увидите приблизительно такое окно:
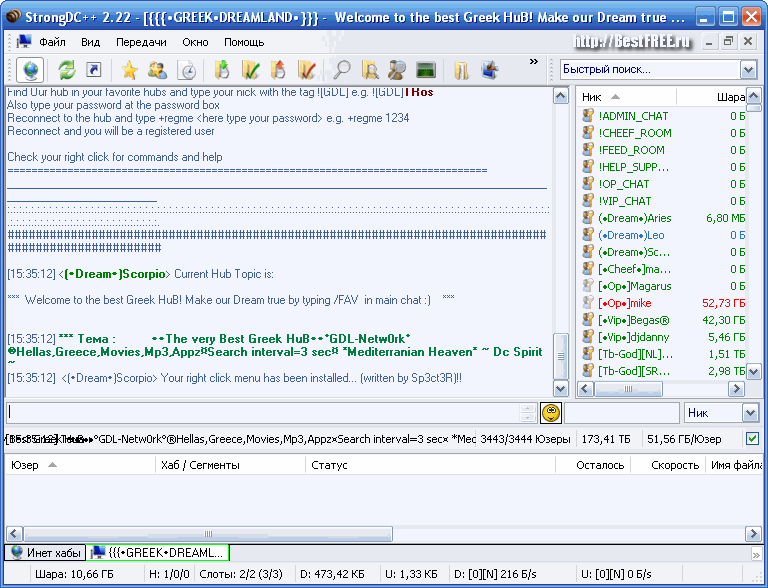
Обратите внимание на наличие закладок под основным окном. При помощи этих закладок в Strong DC++ осуществляется вся навигация. Управлять закладками можно нажатием правой кнопки мыши.
Интерфейс StrongDC++
Основное пространство занимает чат – очень выгодная вещь. Он будет полезен, начиная c того, чтобы «просто поболтать», до возможности узнать у других, где найти ту или иную информацию, если поиск не помог.
Справа от чата находится список юзеров, которые в данный момент присутствуют на хабе. Цвета, которыми написаны имена пользователей, несут дополнительную информацию.

Ручной поиск файлов для скачивания
Рассмотрим взаимодействие при помощи ручного поиска. Возле каждого из пользователей есть индикатор количества расшаренных файлов. Если у Вас не очень высокая скорость соединения, то лучше выбирайте тех, у кого объем файлов поменьше.

Теперь, когда в «Статусе» появится сигнал о том, что список файлов скачан, внизу откроется еще одна закладка, на которой можно будет посмотреть, какие файлы находятся на компьютере у выбранного Вами юзера.
Чтобы скачать выбранный файл, нажмите на нем правой кнопкой мыши и выберите – «Скачать».

Точно так же мы поступаем, пользуясь поиском. В поисковой строке вводим название нужного нам файла и ждем.
После окончания поиска внизу Вы увидите список юзеров, которые обладают этим файлом. Вы выбираете одного из них, подключаетесь к нему и скачиваете нужные данные.
Выводы
Несмотря на многочисленные преимущества сети DC++, существуют и некоторые недостатки. Конкретно их два. Невозможность скачивания файла, если отключился источник (тот, у кого этот файл есть). И второй недостаток – это, иногда, очень долгая очередь на скачивание.
В целом же система очень даже интересная, а удобной ее делает использование программы StrongDC++.
P.S. Разрешается свободно копировать и цитировать данную статью при условии указания открытой активной ссылки на источник и сохранения авторства Руслана Тертышного.
P.P.S. Предшественниками сети P2P были FTP-серверы, к которым удобнее всего подключаться с помощью вот этой программы:
FTP-клиент FileZilla https://www..php
И пока мы тут сидим и думаем, куда бы разместить свою рекламу, в Пало-Альто происходит что-то странное. Там сотрудники маленького магазина Hassett Ace Hardware, продающего хозяйственное оборудование, показывают, как может стать жизнью древняя мудрость о том, что «люди созданы не для накопительства, а для обмена».
Это называется «Ремонт-кафе». Каждые выходные под боком у магазина открывается площадка, где любой человек может бесплатно отремонтировать что угодно. Но при этом ему придется внести свою лепту в то, что происходит на этой площадке. Пока менеджер магазина занимается обычными продажами, пять других сотрудников организовывают толпы желающих «починится» людей, привлекая их к другим ремонтам.
Все делятся знаниями, советами и хорошим настроением. Продажи идут в гору (для ремонта же часто нужны детальки, которые надо купить в магазине). За апрель силами округи было отремонтировано около 130 «единиц техники», в том числе гигантский садовый лавовый фонтан и 200-летняя швейная машинка. Каждый, кто отремонтировался на площадке Hassett Ace Hardware, получает флажок для велосипеда с логотипом компании. И его с удовольствием берут, потому что классное обслуживание – вещь чертовски приятная и незабываемая.
Такая экономика взаимовыгоды получила в маркетинговых кулуарах имя peer-to-peer или «равный равному». Она строится не только на деньгах, но и на высокой степени эмоционального удовлетворения, а в случае маленьких магазинов вроде Hassett Ace Hardware еще и на выстраивании почти интимных отношений с клиентами. Ходят слухи, что эту технологию уже «обнюхивают» такие гиганты, как Pepsi, Chevrolet и Unilever.
«Мы узнали интересную вещь: молодые покупатели, прежде чем прийти в салон за авто, выискивают в социальных сетях странички наших продавцов, чтобы изучить их интересы и найти человека, близкого по духу. Они его находят и советуются с ним, потому что знают – помощь будет больше дружеской, чем менеджерской» — говорит Кристи Лэнди, менеджер по маркетингу в General Motors. Даже экспертное мнение может быть предметом взаимовыгодного обмена.
Давайте отвлечемся от запретов в различных странах, давайте не будем думать, что P2P - механизм обхода блокировок.
Предлагаю вам альтернативное мнение на P2P - какие проблемы будущего и настоящего сможет решить данная архитектура информационных сетей.
Что такое настоящий P2P ?
Давайте введем понятие - настоящий P2P .Настоящий P2P - это одноранговая сеть, в которой абсолютно все узлы сети выполняют одинаковые функции или автоматически могут изменять набор своих функций в зависимости от окружающих условий.
Изменение функций - это ничто иное как предоставление тех функций которые не могут работать у некоторых узлов одноранговой сети из-за ограничений:
1) За NAT"ом
2) Мобильные устройства
Оба класса устройств либо не могут иметь прямой доступ к сети (NAT) или могут, но строго не рекомендовано - (Мобильные устройства) из-за повышенного энергопотребления при огромном количестве подключений.
Для устранения данной проблемы используются такие технологии как TCP Relay (тк большинство P2P систем используют UDP, с огромным количеством одновременных подключений можно выбрать себе узел который будет выполнять функции получения запросов из сети по UDP и пересылки их на конечное устройство по TCP через одно и тоже соединение) Хочу напомнить, что подобный механизм уже был очень давно реализован в Skype, до его покупки компанией MS эти функции работали, позднее - понятие «супер ноды» в Skype ушло и их заменяют сервера MS.
Очень важно не путать P2P и Mesh сети. P2P - это одноранговое взаимодействие на уровне 3 и выше по модели OSI, Mesh - на 3 и ниже соответственно.
Какие проблемы решает P2P сети и какие технологии уйдут при повсеместном внедрении P2P?
Кэширование
В нынешнее время, некоторые провайдеры, а практически все операторы сотовой связи кэшируют трафик. Таким образом достигается экономия ресурсов и аплинков, что бы не гонять одинаковый трафик через магистрали.Но зачем нужно кэширование, если контент попавший в сеть оператора при повторном запросе скорее всего будет запрошен из сети оператора?
При этом не надо строить никакой новой инфраструктуры вообще.
CDN
Система доставки контента используется в основном для доставки «тяжелого» контента, музыки, видео, игровых образом (steam), что бы снизить нагрузку на основной сервер и снизить время отклика - в разные страны и/или регионы ставиться CDN сервера, которые выполняют функцию балансировки нагрузки.Данные сервера нужно обслуживать, затрачивая человека-часы их надо настраивать и они не смогут динамически увеличить свою пропускную способность или допустим:
В Нижнем Новгороде всегда был популярен сервис Giwi.get который позволяет в он-лайне смотреть легальный контент, CDN сервер в регионе может одновременно предоставить возможность просмотра фильмов и сериалов только 100 000 пользователей. Но внезапно на сервисе появляется новый контент (сериал) по прогнозам которые были сделаны на основе исследований, данный сериал не должен был заинтересовать людей из данного региона.
Но почему, то он заинтересовал, и все решили его посмотреть - естественно CDN не справиться, в лучшем случае контент сможет обработать соседний CDN, но не факт что CDN соседний готов к такой нагрузке.
Нехватка каналов связи
Провайдеры последней мили готовы предоставить каналы в 1 Гигабит/с, и даже сеть внутри города сможет прокачать такую нагрузку, но вот незадача, от города идет магистральный канал, который не рассчитан на такую нагрузку, а расширение канала - это миллионы (подставьте валюту на выбор).Естественно, данную проблемы опять же решают P2P сервисы, достаточно что бы в городе был хотя бы 1 источник контента (предварительно скачанный через магистраль) - все будут иметь доступ к контенту на максимальной скорости локальной сети (внутригородской)
Укрепление распределенности интернета
В нынешнем мире Аплинки - это всё, точки обмена трафика есть в городах, но провайдер скорее купит себе еще пару гигабит на магистрали, чем расширит каналы до точки обмена трафика или подключиться к соседним провайдерам.Уменьшение нагрузки на аплинки
При использовании P2P - вполне логично, что провайдеру будет важнее иметь более широкие внутренние каналы, чем внешние, да и зачем платить за дорогостоящий аплинк, если с большой долей вероятности требуемый контент может быть найден в сети соседнего провайдера.Провайдеры кстати тоже будут рады, даже сейчас провайдер предоставляет такие тарифы, что его аплинк не ровняется суммарному количеству всех пользователей.
Другими словами - если все пользователи начнут использовать на 100% свой тариф - аплинк у провайдера закончиться очень быстро.
Очевидно, что P2P решения дают возможность провайдеру сказать, что он предоставляет вам доступ к сети на скорости хоть 1 TB\c тк контент в сети очень редко бывает уникален, провайдер (который имеет пирсинг с соседями провайдерами из города) сможет с большой долей вероятности предоставить доступ к контенту на тарифной скорости.
Никаких лишних серверов в сети
Сейчас в сети провайдера обычно стоят такие сервера как: Google CDN (/Youtube), Yandex CDN/пиринг, DPI, + другие специфические сервера CDN/Кэширования которые используются в данном регионе.Очевидно, что можно ликвидировать все CDN сервера и лишний пиринг (с сервисами, а не с провайдерами), DPI в такой ситуации тоже будет не нужен, тк в часы ЧНН не будет таких резких скачков нагрузку. Почему?
ЧНН - Забудьте эту аббревиатуру
ЧНН - Час наибольшей нагрузки, традиционно это утренние часы и вечерние часы, причем всегда заметны несколько пиков ЧНН в зависимости от рода занятости людей:Пики вечернего ЧНН:
1) Возвращение школьников из школы
2) Возвращение студентов из вузов
3) Возвращение работников которые работают по графику 5/2
Данные пики вы сможете увидеть на любом оборудовании которое анализируют сетевую нагрузку на канал.
P2P Решает и эту проблему, тк велика вероятность, что контент который интересен школьникам может быть интересен как студентам так и работникам - соответственно он уже есть внутри сети провайдера - соответственно ЧНН на магистрали не будет.
Далёкое будущее
Мы отправляем свои аппараты на луну и на марс, уже давно есть интернет на МКС.Очевидно, что в дальнейшем развитие технологий позволит осуществлять полёты в далёкий космос и длительное нахождение человека на других планетах.
Они тоже должны быть связаны в общую сеть, если мы рассматриваем классическую систему Клиент-Сервер, и сервера расположены на земле, а клиенты скажем на Марсе - Пинг убьет любе взаимодействие.
А если мы предполагаем, что на другой планете будет наша колония которая будет расти - то как и на земле они будут пользоваться интернетом, понятное что им нужны будут те же инструменты, что и нам:
1) Мессенджер
2) Соц-сети
И это минимально-необходимое количество сервисов которые позволяют обмениваться информацией.
Логично, что контент который будет генерироваться на Марсе будет интересен и популярен на марсе, а не на земле, как быть соц.-сетям?
Устанавливать свои сервера которые будут автономно работать и через некоторое время синхронизироваться с землёй?
P2P сети решать и эту проблему - на марсе у источника контента свои подписчики, на земле - свои, но соц.-сеть одна и та же, но если у Марсианского жителя будет подписчик с земли - нет проблем, при наличии канала контент прилетит и на другую планету.
Что важно отметить - не будет рассинхронизации, которая может случиться в традиционных сетях, не надо устанавливать никаких лишних серверов там и даже что-то настраивать. P2P система позаботиться сама о поддержке актуальности контента.
Разрыв каналов
Вернемся к нашему мысленному эксперименту - на марсе живут люди, на земле живут люди - все они обмениваются контентом, но в один прекрасный момент происходит катастрофа и связь между планетами пропадает.При традиционных клиент-серверных системах мы можем получит полностью неработающую соц.-сеть или другую службу.
Помните, что у каждого сервиса есть центр авторизации. Кто будет заниматься авторизацией, когда канал нарушен?
А марсианские тинэйджеры тоже хотят постить фотографии своей марсианской еды в MarsaGram.
P2P Сети при разрыве канала с легкостью переходят в автономный режим - в котором она будет существовать полностью автономно и без какого-либо взаимодействия.
А как только связь появиться - все службы автоматически синхронизируется.
Но марс - это далеко, даже на земле могут быть проблемы с разрывом канала связи.
Вспомните последние громкие проекты Google/Facebook с покрытием новых территорий интернетом.
Некоторые уголки нашей планеты всё еще не подключены к сети. Подключение может быть слишком дорогим или экономически не оправданным.
Если же в таких регионах стоить свою сеть (интранет) с последующим подключением её к глобальной по средствам очень узкого канала - спутника, то P2P решения позволяет на начальном этапе пользоваться всеми функциями как и при глобальной связанности сетей. А в последствии - как мы уже говорили выше - позволяет прокачать весь нужный контент через узкий канал.
Выживаемость сети
Если мы полагаемся на централизованную инфраструктуру у нас вполне конкретное количество точек отказа, да, есть еще и резервные копии и резервные дата-центры, но надо понимать, что если основной ДЦ будет поврежден из-за стихии, доступ к контенту будет замедлен в разы, если вообще не прекратиться.Вспоминаем ситуацию с марсом, все устройства поступают на марс с земли, и в один прекрасный день сервер компании Uandex или LCQ ломается - перегорел контроллер RAID, или другая неисправность - и все марсиане опять же без MarsiGram или того хуже - не смогу обмениваться простыми сообщениями друг с другом. Новый сервер или его компоненты приедут с земли ох как не скоро.
При P2P решении - выход из строя одного участника сети никак не сказывается на работе сети.
Я - не могу представить будущее в котором наши системы останутся клиент-серверными, это сгенерирует огромное количество ненужных костылей в инфраструктуре, усложнит поддержку, добавит точки отказа, не позволит произвести масштабирование когда оно понадобиться, потребуются огромные усилия, если мы захотим что бы наши клиент-серверные решения работали не только на нашей планете.
Так, что будущее - это определенно P2P, как изменил мир P2P можно наблюдать уже сейчас:
Skype - небольшая компания не тратила деньги на сервера смогла вырасти до огромного гиганта
Bittorrent - OpenSource проекты могут передавать файлы не нагружая свои сервера
Это только два ярких представителя информационной революции. На подходе множество других программ которые изменят мир.
Одна из первых пиринговых сетей, создана в 2000 г. Она функционирует до сих пор, хотя из-за серьезных недостатков алгоритма пользователи в настоящее время предпочитают сеть Gnutella2 .
При подключении клиент получает от узла, с которым ему удалось соединиться, список из пяти активных узлов; им отсылается запрос на поиск ресурса по ключевому слову. Узлы ищут у себя соответствующие запросу ресурсы и, если не находят их, пересылают запрос активным узлам вверх по “дереву” (топология сети имеет структуру графа типа “дерево”), пока не найдется ресурс или не будет превышено максимальное число шагов. Такой поиск называется размножением запросов (query flooding).
Понятно, что подобная реализация ведет к экспоненциальному росту числа запросов и соответственно на верхних уровнях “дерева” может привести к отказу в обслуживании, что и наблюдалось неоднократно на практике. Разработчики усовершенствовали алгоритм, ввели правила, в соответствии с которыми запросы могут пересылать вверх по “дереву” только определенные узлы - так называемые выделенные (ultrapeers), остальные узлы (leaves) могут лишь запрашивать последние. Введена также система кеширующих узлов.
В таком виде сеть функционирует и сейчас, хотя недостатки алгоритма и слабые возможности расширяемости ведут к уменьшению ее популярности.
Недостатки протокола Gnutella инициировали разработку принципиально новых алгоритмов поиска маршрутов и ресурсов и привели к созданию группы протоколов DHT (Distributed Hash Tables) - в частности, протокола Kademlia, который сейчас широко используется в наиболее крупных сетях.
Запросы в сети Gnutella пересылаются по TCP или UDP, копирование файлов осуществляется через протокол HTTP. В последнее время появились расширения для клиентских программ, позволяющие копировать файлы по UDP, делать XML-запросы метаинформации о файлах.
В 2003 г. был создан принципиально новый протокол Gnutella2 и первые поддерживающие его клиенты, которые были обратносовместимы с клиентами Gnutella. В соответствии с ним некоторые узлы становятся концентраторами, остальные же являются обычными узлами (leaves). Каждый обычный узел имеет соединение с одним-двумя концентраторами. А концентратор связан с сотнями обычных узлов и десятками других концентраторов. Каждый узел периодически пересылает концентратору список идентификаторов ключевых слов, по которым можно найти публикуемые данным узлом ресурсы. Идентификаторы сохраняются в общей таблице на концентраторе. Когда узел “хочет” найти ресурс, он посылает запрос по ключевому слову своему концентратору, последний либо находит ресурс в своей таблице и возвращает ID узла, обладающего ресурсом, либо возвращает список других концентраторов, которые узел вновь запрашивает по очереди случайным образом. Такой поиск называется поиском с помощью метода блужданий (random walk).
Примечательной особенностью сети Gnutella2 является возможность размножения информации о файле в сети без копирования самого файла, что очень полезно с точки зрения отслеживания вирусов. Для передаваемых пакетов в сети разработан собственный формат, похожий на XML, гибко реализующий возможность наращивания функциональности сети путем добавления дополнительной служебной информации. Запросы и списки ID ключевых слов пересылаются на концентраторы по UDP.
Вот перечень наиболее распространенных клиентских программ для Gnutella и Gnutella2: Shareaza, Kiwi, Alpha, Morpheus, Gnucleus, Adagio Pocket G2 (Windows Pocket PC), FileScope, iMesh, MLDonkey